Visual overview of a custom malloc() implementation#
This post was discussed on Hacker News.
C programmers will undoubtedly recognize the standard function malloc(), the language's memory allocator and close confident of everyone's favorite segfaults. malloc() is the mechanism through which programs obtain memory at runtime, and it often ends up being the primary way in which objects are created and managed. Considering this central status, I'm surprised that most programmers treat it as a black box. This post is a bit of an excuse to tell you more about what happens under-the-hood and look at one possible implementation.
In a typical use case, memory is allocated by calling malloc() with a requested number of bytes as parameter. malloc() returns a pointer through which the memory can be used before being returned to the system by calling free() :
1 2 3 4 5 6 7 | |
This simple piece of code raises at least three important questions:
- Where does the memory actually come from?
- How are we able to allocate variables of any type without even telling
malloc()the type that we want? - How does
malloc()keep track of the address and size of everything we allocated?
Let's go on a little adventure to answer all of these.
TL;DR for avid readers: it's a segregated best-fit with 16 classes, single-threaded, very standard.
The heap originates from the system#
The first question “Where does the memory actually come from?” leads us into system land, since the short answer that you might expect is the operating system is providing it. That's fine and all, but how do we get from that abstract concept to an actual pointer that we can write to?
In a classical userspace#
On classical operating systems, each userspace process lives in its own address space, where its code, libraries, and data are all loaded. Having separate address spaces for each processes is a key design feature for operating systems, and I'd get lost if I talked about why this is. The TL;DR is that it avoids processes reading or writing each other's memory (which nowadays is mostly for security) and that it's managed in hardware by an MMU.
The exact layout of the address space depends on the operating system. It can be anything; frankly you could make one up for breakfast and be fine.(1) A simple example might look something like this (we'll go over the contents in a minute):
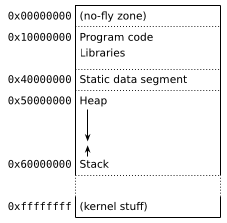
Such an address space is called a virtual address space because it doesn't actually own any memory. The real memory in the computer (the RAM chip) exists as a big block(2) in the so-called physical address space; but of course any process with full access to the entire RAM would be cybergod, so only the kernel is allowed to use it. Normal processes get access to memory when the kernel lends them some by mapping it to their virtual address space:
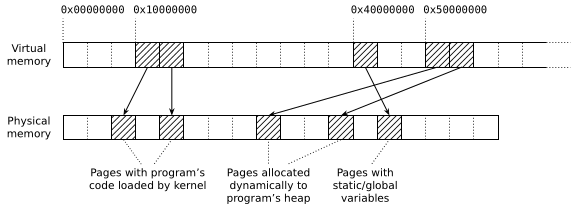
This process is called paging. Essentially, both the virtual and physical address spaces are divided into pages (of varying size but most commonly 4 kB) and the kernel decides which pages of virtual memory should be mapped to which pages of physical memory. When the program makes a memory access, the CPU checks if the accessed pointer falls into a mapped page. If so, then the associated physical page is accessed. Otherwise, the access is streng verboten and the program crashes with a segfault.(3) This gives the kernel complete control over what memory processes can read and write, and thus achieves the separation goals I mentioned earlier.
So let's go back to the layout from earlier. In it, we find:
- Program code: This is loaded straight from the program's executable file.
- Libraries: Dynamic libraries loaded at startup, basically the same as code.
- Static data segment: This segment contains global and static variables.
- The stack: This is where functions' local variables are stored.
- The heap: This is the memory managed by
malloc().
Since code is read-only and the data segment is static (meaning its size is fixed before running the program), the only two regions that can grow during execution are the stack and heap. The stack itself is quite small; on Linux, ulimit -s will tell you its maximum size, which is typically 8 MB. It also comes with very strict lifetime limits, since any object created there is destroyed when the function creating it returns. This leaves the heap. On your personal computer or phone, heap data accounts for a vast majority of memory used by programs. When your web browser hogs 5 GB of memory then it's basically 5 GB of heap.(4)
Like everything in the virtual address space, heap is created when the kernel maps pages of physical memory at a suitable virtual address. So the answer to the question “where does the memory come from?” is “the kernel maps new pages into the address space”. The process requests this by invoking the syscall sbrk(2), and if the kernel allows it then new pages are mapped and pointers to the pages become valid. You can see this in action in pretty much any Linux-supporting allocator. For example, the glibc allocator implements this “get more memory” primitive in morecore.c and the call boils down to an indirect invocation of sbrk(2).
So, to sum up: malloc() gets memory by asking the kernel with sbrk(2) and the kernel provides it by mapping entire pages (of 4 kB or more). Then, malloc()'s job is to split up these pages into blocks of user-requested size while keeping track of what's used and what's free.
In embedded systems#
Of course, not all systems run a full-fledged kernel with paging-based virtual memory. There are plenty of other options, but the core mechanics remain the same. On many embedded systems, a fixed region of memory is provided for the heap; in that case malloc() just cannot expand. Allocators are pretty good at dealing with fixed-, variable- and pineapple-shaped memory so they don't really care. The core of the design is really how they split and manage the memory they get.
Making variables out of raw memory using “maximal alignment”#
So far, I've only talked about memory as raw data — sequences of bytes arranged in pages that the program can read and write. But what we want from malloc() is really to create variables. The C language constantly insists on having us declare the type of variables, so how are we able to create them with malloc() from just a size?
1 2 3 4 | |
You might think that I did declare the type for the allocation by writing int *j, but that's not the case. In terms of typing the second definition really has two steps: first the compiler types malloc(4), on its own without any context, then it checks that the assignment is legal, ie. that the type of malloc(4) is convertible to int *. This is an important property of C: expressions are always typed out of context, independently from what you do with it. C++ programmers may be more familiar with this concept as “return types do not contribute to overload resolution”.(5)
What's happening here is that malloc(4) is of type void *, i.e. a universal pointer, which is convertible to any non-function pointer type. No information related to the type of j is communicated to malloc(). So the question remains: how is malloc() able to allocate suitable memory without knowing the desired type?
It turns out that suitable memory really boils down to two things. In order to contain a variable of type T, a region of memory must:
- Have a size at least
sizeof(T); - Have an alignment greater than or equal to the alignment of
T.
Alignment refers to the highest power of two which divides an address. For architectural reasons values of certain basic types are constrained to be stored on aligned boundaries. Typically, primitive values occupying N bytes (with N a power of two) will be stored exclusively at addresses that are multiples of N. So a 1-byte char can be stored at any address, but a 2-byte short only on even addresses, a 4-byte int on addresses that are multiples of 4 (called “4-aligned”), etc.
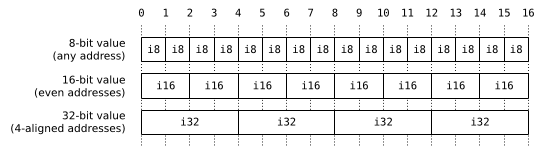
Only basic types (integers, floating-point numbers and pointers) have architectural alignment requirements, so if you work out the layout of structures, unions and other composite types, you will find that every type ends up with the alignment requirement of a basic type.(6) This means that the largest alignment requirement of any basic type (max_align_t in C++, usually 4 bytes for 32-bit architectures and 8 bytes for 64-bit architectures) is suitable for every single type in the language.
The existence of a universal alignment solves our mystery, since malloc() can simply return maximally-aligned pointers in order to accommodate any data type. Unsurprisingly, this is exactly what good ol' C99 explicitly requires it to do [ISOC99 §7.20.3.1]:
The order and contiguity of storage allocated by successive calls to the
calloc,malloc, andreallocfunctions is unspecified. The pointer returned if the allocation succeeds is suitably aligned so that it may be assigned to a pointer to any type of object and then used to access such an object or an array of such objects in the space allocated (until the space is explicitly deallocated).
Most implementations of malloc() are parametrized by this alignment. In my case, I'm working on a 32-bit architecture so the highest alignment I have to work with is 4. As you will see shortly, this bleeds onto block and header sizes, which are going to be multiples of 4.
Tour of a segregated best-fit implementation#
Ok, so an implementation of malloc() essentially has to:
- Manage an area of memory which is either fixed or extended by mapping new pages with
sbrk(); - Carve out maximally-aligned blocks to respond to allocations;
- Keep track of enough information to make sure no two live blocks ever intersect.
The third point is where all the variety in implementation comes from. There's about a million designs for memory allocation strategies, data structures, not to mention garbage collectors, and I'd by lying if I pretended I could give you a visual overview of that. You can find a general introduction in the fantastic paper Dynamic storage allocation: A survey and critical review [Wilson1995].
And that's about all the generalities I have for you. The rest of this article will go through an implementation of the segregated best-fit algorithm that I wrote for gint. You can find the original code in gint's repository at src/kmalloc/arena_gint.c; here I'll start from intuitions and work my way up to (hopefully) understandable versions of malloc() and free() by alternating visuals and C code.
Note that the code is meant to be readable without context but isn't quite complete (some initialization is missing mostly).
Block structure and navigating the sequence#
As is typical with general-purpose allocators, I keep track of the metadata for each allocation in a short header before the allocated space itself. Which means that the heap region is made of blocks of the following shape:
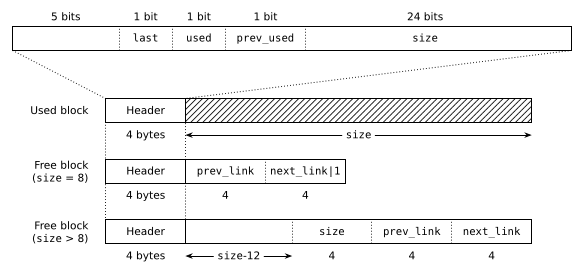
The simplest type of block is used blocks: they consist of a 4-byte header followed by user data represented by the hashed region. malloc() returns a pointer to the user data and that's all you ever see from the outside. The header records the size of the block and information that's useful for navigating the heap to find other blocks. This is the corresponding structure definition:
1 2 3 4 5 6 7 | |
Free blocks have the same 4-byte header, but they also contain extra data in their footers. That's the nice thing about free blocks: no data is being stored, so we might as well use the space to maintain the data structure. prev_link and next_link are used to connect some linked lists; I'll discuss that in a minute. All we need to know for now is that these are pointers to other blocks.
Blocks are stored immediately next to each other with no spacing, forming a long sequence that covers the entire heap region (the arena), apart from a small index structure placed at the start:

The two non-trivial flags in the block_t header are both related to this sequence: last marks the last block, and prev_used is a copy of the previous block's used flag, which has the following (quite tasty!) use.
Notice how we can pretty easily navigate the sequence forwards: from a pointer to the start of a block we can find a pointer to its end (ie. to the start of the next block) because the block's size is indicated in the header.

The code is as straightforward as you'd expect:
1 2 3 4 5 6 | |
Well, it turns out that free blocks are set up so that you can also do the opposite and find the start of a free block from its end. This boils down to determining the size from the footer, which is indeed possible:
- Free blocks of size ≥ 12 simply store their size at offset -12 from the end.
- Free blocks of size 8 appear completely filled by
prev_linkandnext_link, but if we look closely it turns out that there are actually 4 bits available. This is becauseprev_linkandnext_linkare pointers to other blocks, thus multiples of 4 (since blocks are 4-aligned). Therefore, the 2 low-order bits of both pointers are always 0, and I can steal one of them to store a flag that identifies 8-byte blocks.
So now, when we have a pointer to the end of a free block, we can look up the low-order bit of next_link; if it's 1 the block is of size 8, otherwise we can read the size from offset -12. In both cases we can recover a pointer to the start of the block:
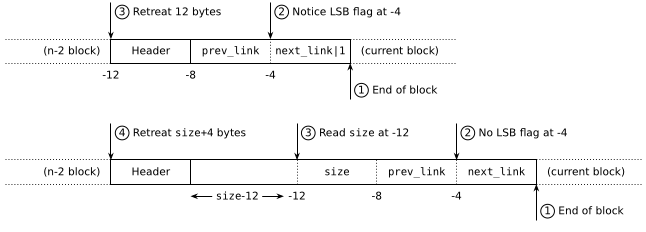
Of course, in order to use this for reliable backwards navigation we need to know whether the previous block is in fact free or not. This is the purpose of the prev_used flag in the block header, and the technique as a whole is known as the boundary tag optimization — paying a single bit for the luxury of navigating back through empty blocks.
1 2 3 4 5 6 7 8 | |
The benefit of this little operation should be clear by the next section, but if you're curious you can already try to figure it out.
Quick aside. Tightly packing blocks is an obvious choice when considering memory usage and the need to not waste any space. It also makes writing out-of-bounds of dynamically-allocated arrays quite lethal, as that immediately corrupts the next block, basically guaranteeing a crash at the next malloc() or free(). This might seem like a problem but it's actually a good thing: it makes out-of-bounds writes more visible which leads to empirically faster bug resolutions (in fact, introducing this new allocator in gint led to a mini-wave of new crashes that all turned out to be application bugs).
Merging and splitting in the sequence#
As this point you might be wondering how we get from an empty, freshly-initialized heap to the mess of a sequence that I've pictured previously, with data spread around instead of being nicely arranged on one end with a nice, large block of free memory on the other end.
The short answer is you can't avoid the mess. The user is completely in control of allocated blocks, and in particular they can free them in any order, creating holes at any moments. Since we don't know how long blocks will live when they are allocated (... the user might not either!) it's hard to plan ahead.
There's one thing we can do to keep the sequence as tidy as possible, though: we can merge adjacent free blocks to make larger blocks. This increases the chance that we can answer large malloc() requests and ensures that if the user were to free every block we'd recover one large empty block spanning the entire heap.
With this simple idea in mind, we can now work out what malloc() and free() will have to do. We'll stick to a general procedure for now and go over the actual code at the end.
malloc(N):- Search for
b, the smallest free block of size ≥Nin the sequence. - If none is found, we're out of memory, return
NULL(... or usesbrk()to get more and retry). - If the size of
bis strictly larger thanN+4, splitbin two to keep some free memory. - Mark
bas used and return it.
Step 1 is what makes this algorithm a best-fit, as it finds the “best” block for the allocation (the one that's as close as possible to the requested size). Confusingly this isn't necessarily the best choice(7), and there are many other strategies. Anyway, the interesting part for now is that if we decide on a block that's larger than needed, we split it off so we don't waste any memory:
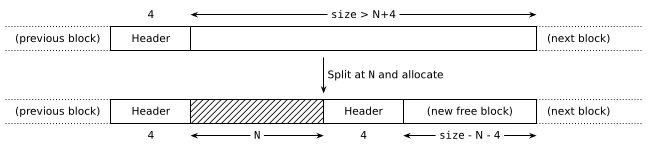
The function to do that is pretty straightforward, the only subtlety being the maintenance of prev_used flags in nearby blocks.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Of course we want this splitting to be as temporary as possible; if at any point in the future both blocks are free again, we need them merged back. Fortunately this is fairly easy to track down; all cases of adjacent free blocks are caused by a free(), and we can catch 'em all if we simply merge newly-freed blocks with their neighbors.
free(ptr):- Find the associated block
b = ptr-4. - Mark
bas free. - If the successor of
bexists and is free, merge it intob. - If the predecessor of
bexists and is free, mergebinto it.
In the best case where both neighbors are free, the operation looks like this:
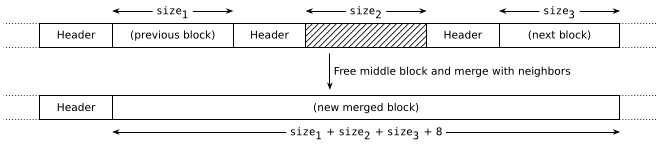
Merging is even simpler since we erase headers instead of adding them:
1 2 3 4 5 6 7 8 9 10 11 12 | |
And this is why the boundary tag optimization is useful: it lets us find the previous block if it's free and merge it, even when we are dropped in the middle of the sequence by the user-provided ptr.
Segregated linked lists#
Now you could go ahead and implement step #1 of the malloc() algorithm (find the smallest block of size ≥ N) naively, by checking every block in the sequence in order. You'd get a working and standard best-fit allocator, which honestly is very much viable for small embedded systems. However, if you have a large heap (say, 1 MB) you'll end up checking a lot of blocks and programs that allocate frequently will be bottlenecked by the allocator.
Now is the time were you can go on deep, fascinating studies about the allocation patterns of various programs, where you can treat blocks with different lifetimes separately, design better APIs where more information is communicated to enable better memory planning, and otherwise grind the response time down to absolute perfection.
I'm just going to make the easy assumption that the amount of work being done with a block is correlated to its size. So small block means little work means malloc() needs to answer quickly to not be the bottleneck. Large blocks means a lot of work so it's acceptable to be slower. This is undeniably an approximation, but still generally true.
To speed up the response time for small blocks (which also happen to be the most common), I'm going to partition free blocks into linked lists of related sizes:
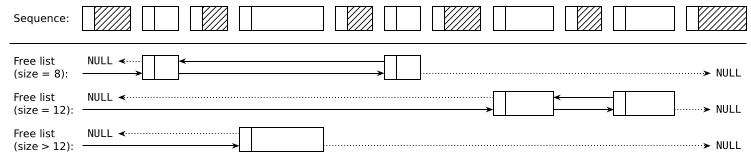
These are standard doubly-linked lists using the prev_link and next_link attributes stored in free blocks' footers. Unlike what the figure suggests, blocks in each linked list do not have to sorted by increasing address, it's just way more readable when represented this way.
The implementation has 16 lists holding blocks of the following sizes, which are easily classified by a small function.
- Small blocks (14 lists): 8 bytes, 12 bytes, ..., 60 bytes
- Medium blocks: 64 — 252 bytes
- Large blocks: ≥ 256 bytes
1 2 3 4 5 6 7 8 | |
Holding pointers to these lists is the purpose of the index structure I mentioned earlier. It also keeps track of heap statistics, which I've left out of this presentation for simplicity.
1 2 3 4 | |
The big idea here is that small requests are generally served in constant time because the first 14 lists with small blocks never need to be traversed. All the blocks in there are interchangeable, so we can always just take the first. Only the last two lists need to go through an actual best-fit search, and we only use them to answer small requests if every suitable small list is empty.
I'll spare you the code for manipulating the linked lists since it's very standard. Let's just say that remove_link() removes a free block from its associated list and prepend_link() adds it back at the start. best_fit(list, N) looks for the smallest block of size ≥ N in a list.
1 2 3 4 5 6 | |
You've probably figured it out by now but this is where the name “segregated best-fit” comes from, as blocks of different sizes are partitioned (segregated) into appropriate doubly-linked lists.
Final implementation of malloc() and free()#
We can now write the entire malloc() and free() functions. In malloc(), we round the request size up and then look for a free block in the associated linked list. If the list is empty, we go up to the next list until we either find a large block that can be split, or realize that we're completely out of memory.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
In free(), we mark the block as free, merge it with its free neighbors (after removing them from their own linked lists) and finally insert the resulting block back into the index.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
Segregated fits are not particularly fancy allocation algorithms, but as you can see they're simple and compact enough to be explained in an Internet article (... if I've done my job right that is!). These are still non-trivial allocators and I think that's notable for a feature that's usually only presented as a mysterious black box.
Closing remarks#
Performance#
I don't have much to offer in the way of performance evaluation. To be honest, this algorithm doesn't have any particularly good qualities despite responding fast in general for small requests. In terms of fragmentation (breaking up the heap region in too many small pieces that waste memory), best-fit doesn't really shine in general, but few gint applications actually put enough pressure on the heap to fill it and run out of memory. Maybe another time!
realloc() and extensions#
If you look at src/kmalloc/arena_gint.c you will find a bunch of functions that I haven't mentioned here. For the sake of completeness, we have:
realloc(), the other standard function for extending a block. It generalizes bothmalloc()andfree()but it doesn't add any new difficulty in the implementation.malloc_max(), a gint-specific function that allocates the largest block possible. This is useful once in a while when you want to allocate data but you don't know the size in advance and you don't want to fake-generate it first, like inasprintf(). (realloc()can shrink the block once it's filled.)- A bunch of
kmallocdbg_*()functions that check structural invariants. These are useful for finding bugs, but also for forcing the programmer to write down the laws that allocator functions must follow.
Managing multiple arenas#
As a unikernel, gint doesn't provide sbrk() and instead the heap region (the arena) is of a fixed size. However there are quite a few non-adjacent areas of memory that gint applications use, so the implementation makes sure to support multiple arenas so that independent heaps can be created. Extensions with custom allocators are also possible.
If you look at gint_malloc() and gint_free() you will see this extra parameter void *data; that's a generic user pointer passed by the arena manager to each implementation. I used it to access the index structure.
Conclusion#
Well, that's it for this time. I hope this article leaves you with good intuitions about memory management and a sense of understanding for what malloc() actually does in general.
For this article, I wanted to experiment with a mixed visuals-code approach with TikZ. It takes a long time to write up, but I like how it turned out, so I might come back to it.
References#
| Dunfield2021 |
Jana Dunfield and Neel Krishnaswami. 2021. Bidirectional Typing. ACM Comput. Surv. 54, 5, Article 98 (June 2022), 38 pages. https://doi.org/10.1145/3450952 |
| ISOC11 |
ISO/IEC 9899:2011: Information technology — Programming languages — C. International Organization for Standardization, Geneva, Switzerland. https://www.iso.org/standard/57853.html (open draft at open-std.org). |
| ISOC99 |
ISO/IEC 9899:1999: Information technology — Programming languages — C. International Organization for Standardization, Geneva, Switzerland. https://www.iso.org/standard/29237.html (open draft at open-std.org). |
| Wilson1995 |
Wilson, P.R., Johnstone, M.S., Neely, M., Boles, D. (1995). Dynamic storage allocation: A survey and critical review. In: Baler, H.G. (eds) Memory Management. IWMM 1995. Lecture Notes in Computer Science, vol 986. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-60368-9_19 |
-
It matters so little that Linux just puts everything at random addresses to improve security against attacks based on knowing where code is located in virtual memory. ↩
-
I'm simpliyfing a bit here; at the lowest level RAM can appear fragmented in the physical address space. In fact, on x86, it can be anything; see BIOS call
e820if you have extra faith in humanity that you need to get rid of. Ultimately we don't care since everything is split into pages. ↩ -
The term “segmentation fault” was inherited from the ancient time of segmentation, the predecessor to paging. If you don't know what segmentation is, then keep it this way — segmentation was terrible anyway. Page faults are also a thing but only when the kernel maps pages on-demand, which I'm not covering here. ↩
-
Very large allocations on Linux are usually handled by directly asking the kernel for an entire set of pages via
mmap(2). I'm putting that in the same bag asmalloc(). Fun fact: 32-bit virtual address spaces are quite small so fragmentation gets spicy real fast. ↩ -
This is in stark contrast with typing in functional languages, for which bottom-up type inference and top-down type checking typically complement each other in what is known as bidirectional typing [Dunfield2021]. Typing in C/C++ is bottom-up only. ↩
-
You can also require a larger alignment on a type or variable with a compiler-specific attribute. This is called an over-aligned type. Crucially, local variables created with such a type will be properly aligned, but
malloc()will not honor the requirement, so it has to be accounted for manually or using the C11 functionaligned_alloc()[ISOC11 §7.22.3.1]. ↩ -
Mostly because whenever we don't have a perfect match we split hairs off of a slightly larger block than requested and this creates a ton of very small blocks that are very hard to use. ↩